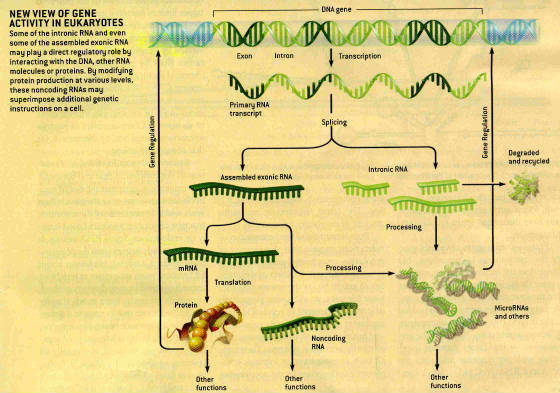
Biologists assumed that proteins alone regulate the genes of complex organisms because they had
not until recently discovered the regulatory system based upon the introns in DNA. The
standard dogma in molecular biology for the past half a century has stated that genetic information encoded in DNA is transcribed
as intermediary molecules of RNA, which are in turn translated into the amino acid sequences that make up proteins. The prevailing assumption was one gene, one protein. A
corollary has been that proteins, in addition to their structural and enzymatic roles in cells, must be the primary agents
for regulating the expression and activation of genes.
Introns, “junk DNA” are absent in prokaryotes.
Less than 1.5% of the human genome code for protein. Some amoebaes have
1,000 more DNA than humans; some amphibians have 5x more DNA as mammals do. The
nematode work Caenorhababditis elegan (made of about 1,000 cells) has about 19,000 protein-coding genes, almost as
much as the human’s 25,000. Around 99% of the proteins in humans have recognizable
protein equivalents in mice, and vice versa
Many genes in complex organisms do not encode protein but instead give rise to RNAs with direct
regulatory function. Thousands of RNAs that never get translated into protein
(noncoding RNAs) have been identified in recent analyses of transcription in mammals.
Between half & 3/4th of all RNA transcripts fit this category.
Hundreds of “microRNAs derived from introns and larger nonprotein-coding RNA transcripts have recently been identified
in plants, animals, and fungi. Many of them control the timing of processes that
occur during development, such as tem cell maintenance, cell proliferation, and apoptosis.
These RNA signals, by finding targets on other RNAs, DNA, and proteins, could influence a cell’s genetic program
in many ways. They could inform various genes that a particular protein coding
sequence has been transcribed, and that feedback could trigger a host of parallel adjustments.
Other could control trajectories of gene expression.
Chromatin—what makes up chromosomes-- consists of DNA complexed with proteins. Within cells, small chemical tags (such as methyl and acetyl groups) can attach to segments of DNA and
to chromatin proteins and thereby determine whether the genes in the associated DNA will be accessible for transcription or
will stay silent. Recent results indicate that RNA signaling directs the tagging
of the chromatin and thus gene expression.
RNA can encode short, sequence specific signals which can direct RNA molecules precisely to receptive
targets in other RNAs and DNA. When intron RNA is spliced out of a gene’s
transcript, the protein-coding RNA regions may be assembled in more than one way to yield more than one type of protein. Multiple structurally similar forms of the same protein are thus possible without
having a gene for each form. Only a few times has protein factors been responsible
for these alternate forms, the other instances it is from introns. Generating
complexity; (variations in a protein) is easy; however, controlling them so that best ones can be duplicated in the right
situation is difficult
In prokaryotes the regulatory function was performed by DNA (genes); thus limiting the complexity
of such systems because regulatory genes themselves need regulating. Eukaryotes
however developed a regulatory system using RNA. This development helps (along
with 3 embryonic tissue systems up from just 2) to explain the Cambrian explosion. Even
though the overall rate of change (mutation) of introns in greater than exons, there are parts of the introns that have persisted
virtually unaltered for many millions of years. These unchanging islands of sequence
play a vital role, obviously.
A number of genetic diseases such as cystic fibrosis and thalassemia are caused by coding damage
which thus makes a defective protein. Noncoding RNAs have recently been linked
with several conditions, including B cell lymphoma, lung cancer, prostate cancer, autism, and schizophrenia.
About 40% of the genome comprises transponson and other repetitive elements. Their contribution is not well understood. Another process
not well understood is the A-to-I editing (adenosine-to-inosine) editing, in which an RNA sequence changes at very specific
sites. It was demonstrated recently that this editing of RNA transcripts is two
orders of magnitude more widespread in humans than previously thought and overwhelmingly occurs in repeat sequences called
Alu elements that reside in noncoding RNA sequences. A-to-I editing is particularly
active in the brain, and aberrant editing has been associated with a range of abnormal behaviors, including epilepsy and depression. Although RNA editing occurs to some extent in all animals, Alu elements are unique
to primates. An intriguing possibility is that the colonization of primate lineage
by Alu elements make it possible for a new level of complexity to arise in RNA processing and allowed programming for neural
circuitry7 to become more dynamic and flexible. That versatility may have in
turn laid the foundation for the emergence of memory and higher-order cognition in the human species.